首页
产品中心
云算力中心
解决方案
资讯动态
关于蓝剑
联系我们
蓝剑口令库是由公司自主研发的解密类产品,蓝剑口令库依据人工智能的深度学习技术生成1500亿余条口令。口令字典采用专门的压缩算法,既保证了口令覆盖率和平台运算效率,又大幅度降低了数据传输量和磁盘占用空间。超大的口令字典和超强的设备性能相结合,必将在破译实战中转化为更高的破解成功率。
 一级字典 一级字典 |
二级字典 |
三级字典 |
四级字典 |
| 手机号码库 |
4位以下短口令库 |
姓名+年份库 |
| 8位以下数字库 |
姓名库 |
弱口令库 |
内置口令库:1354亿条
一级口令库:6亿条
二级口令库:288亿条
三级口令库:1060亿条
膨 胀 库:5393亿条
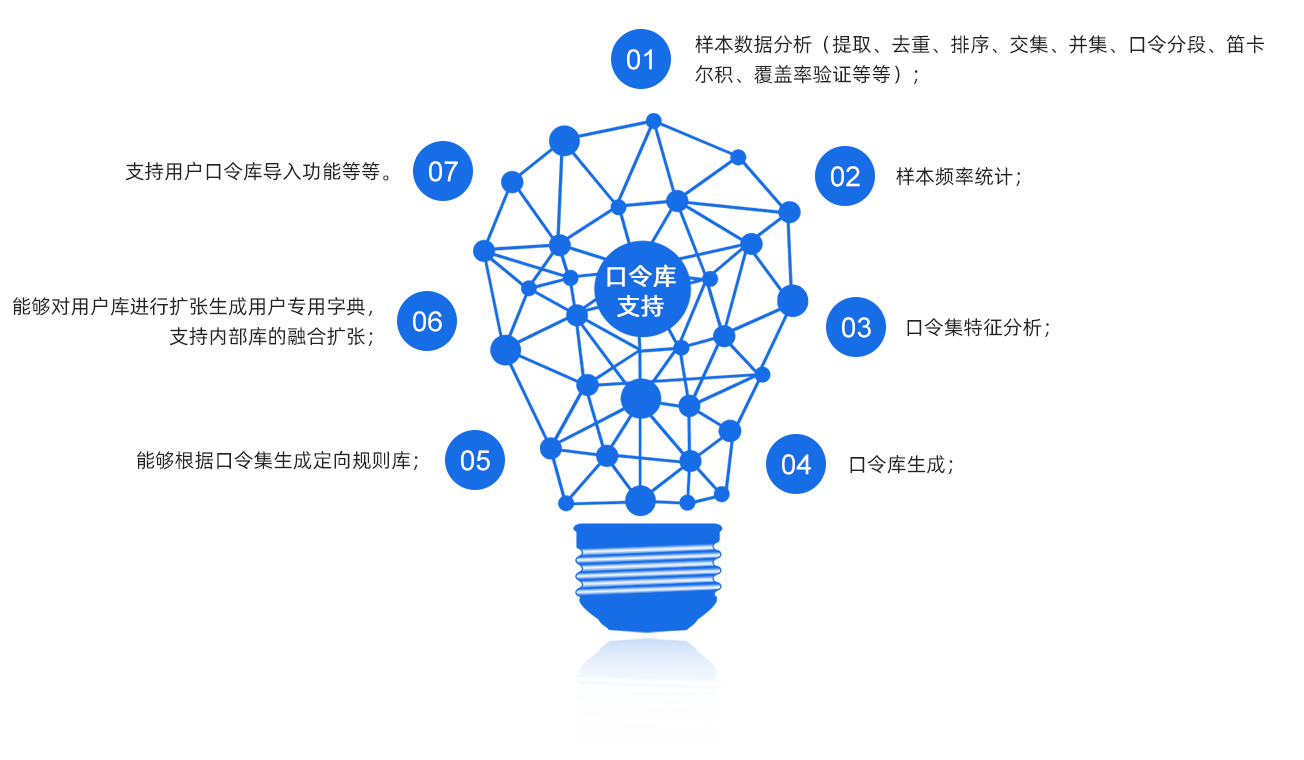
收集了历年来网络上泄露出来的网站爆库数据:领英用户数据库、Myspace用户数据库、163数据库、HashesOrg提供的各网站口令及哈希密文数据)以及各种语言的语料数据。
针对爆库样本数据去重,对假口令进行甄别、剔除,假口令包括:散列值、网页页面编码、人为产生的数据(量大且具有特征)等等。
利用上下文无关语言模型将样本数据分段并统计字符频率:字符单频、首尾字符单频、首尾双字符频率、首尾三字符频率、两字符跟随频率、三字符跟随频率等等。对于常用字符组合进行频率统计:口令中出现的汉语拼音频率、口令首出现的汉语拼音频率、口令中出现的英文姓名频率、口令首出现的英文姓名频率、口令中出现的英文常用8000词频率、口令首出现的英文常用8000词频率、常用键盘序以及其他特殊字符组合频率等要素的统计。
根据统计特征基于马尔可夫模型生成口令库。
根据硬件设备的特点,在设计口令库时并没有保存原始全长度口令,而是分为前后缀字典和穷尽两部分,应用时以字典为基础进行部分的穷尽扩展,这样设计的原因是:
便于硬件进行搜索操作,口令覆盖率更高;
占用存储空间更小(合并了相同前、后缀的口令条目);
更加高效,更少的口令条目(覆盖率更高)使遍历口令的速度更快,效率更高。
网站地图

服务热线
0531-69928563